
Unser tägliches Brot ist die Verarbeitung und Speicherung von teilweise sehr sensiblen Daten. Dabei sollte man sich stets bewusst sein, wie wichtig die Einhaltung von Datenschutzrichtlinien ist. Es ist nicht schwer zu erkennen, wie gefährlich es sein kann, wenn sensible Informationen wie
• Gesundheitsdaten,
• Kontodaten oder
• Kontaktinformationen
weithin zugänglich gemacht werden. Im Umgang mit solchen Daten ist also eine besondere Vorsicht geboten.
Das Bekanntwerden von Datenleaks ist nicht nur für die betroffenen Personen unangenehm, sondern geht auch mit einem erheblichen Imageverlust des ursächlichen Unternehmens einher. Es gab in der Vergangenheit bereits zahlreiche Datenschutzverletzungen, die die Gefahr von Verstößen und die Notwendigkeit der Durchsetzung von Datenschutzbestimmungen bewiesen haben. Der Security Insider gibt für jedes Jahr einen Überblick über solche Verstöße heraus, wie z.B. “Die größten Datenpannen im Jahr 2022“.
Anonymisierung und die DSGVO
Mit der Allgemeinen Datenschutzverordnung (DSGVO), die 2016 beschlossen und 2018 in Kraft getreten ist, werden uns eine Reihe spezifischer Regeln zum Schutz von Nutzerdaten und zur Schaffung von Transparenz zur Seite gestellt. Zu diesen Grundregeln gehören im Wesentlichen:
• Rechtmäßigkeit / Verarbeitung nach treu und glauben
• Transparenz
• Zweckbindung
• Datenminimierung
• Richtigkeit der Daten
• Integrität und Vertraulichkeit der Datenverarbeitung
Eine umfassende Infobroschüre zur DSGVO ist beim Bundesbeauftragten für den Datenschutz und die Informationsfreiheit (BfDI) zum Download bereitgestellt.
Obwohl die DSGVO streng ist, erlaubt sie Unternehmen, anonymisierte Daten ohne Zustimmung zu sammeln, sie für jeden Zweck zu verwenden und sie für unbestimmte Zeit zu speichern – solange Unternehmen alle Identifikatoren aus den Daten entfernen, sie also nicht wieder auf die Person zurückgeführt werden können.
Datenanonymisierung ist somit der Prozess des Schutzes privater oder sensibler Informationen durch Löschen oder Verschlüsseln von Identifikatoren, die eine Person mit gespeicherten Daten verbinden. So können beispielsweise personenbezogene Daten wie Namen, Sozialversicherungsnummern und Adressen durch einen Datenanonymisierungsprozess laufen gelassen werden, bei dem die Datenstruktur erhalten bleibt, die Quelle aber anonym bleibt.
Ziel ist es, den Schutz der Informationen von Personen zu gewährleisten. Die Anonymisierung von Daten minimiert das Risiko von Informationslecks, wenn Daten über Grenzen hinweg verschoben werden. Dadurch, dass die Strukturen der Daten erhalten bleiben, sind Analysen nach der Anonymisierung weiterhin möglich.
Pseudonymisierung vs. Anonymisierung
Eine weitere Möglichkeit bietet die Pseudonymisierung. Während bei der Anonymisierung die personenbezogenen Daten also verborgen werden, bleiben sie bei der Pseudonymisierung zwar lesbar, aber die dazugehörige Person bleibt hinter einem Pseudonym (eine ID, ein Benutzername o. ä.) verborgen und die Identifikation der zum Datensatz gehörenden Person verschleiert. Je nachdem, wie viele und welcher Art der so frei lesbaren Daten zu einem Pseudonym vorliegen, können allerdings Rückschlüsse auf die betreffende Person doch möglich sein. Da es sich bei Pseudonymisierung weiterhin um personenbezogene Daten handelt, fallen sie auch weiterhin in den Anwendungsbereich der DSGVO.
Datenanonymisierung: Unser Fallbeispiel
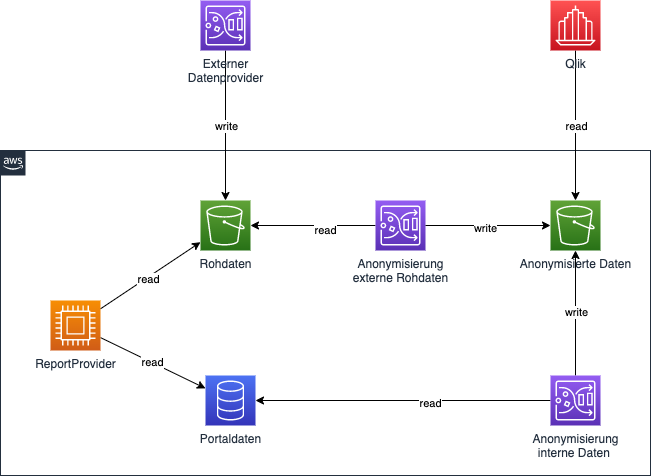
Auch in unserem langjährig bestehenden Portal-Projekt eines größeren Finanzdienstleisters wurde es vor Kurzem notwendig Kunden-Datensätze der BI-Reporting-Software Qlik Sense zur Verfügung zu stellen, ohne personenbezogene und damit sensible Daten mit nach außen zu geben. Hier handelt es sich um ein hybrides Projekt, da es zunächst mit lokaler Infrastruktur gestartet ist. Seit einigen Jahren wurde es jedoch auch um einige Cloud Komponenten von AWS erweitert.
Die für den Report zugrunde liegenden Daten kommen aus zwei Datenquellen, aus denen auch bereits für den internen Gebrauch Reports erstellt werden. Hier ist eine Datenanonymisierung nicht notwendig oder sogar unerwünscht. Bei diesen beiden Datenquellen handelt es sich einerseits um aus projektintern im laufenden Betrieb erfasste und in einer Datenbank gesammelte Daten. Andererseits werden auch von einem externen Anbieter Rohdaten zum Import bereitgestellt, welche in einen Amazon S3 Bucket vorgehalten werden.
Amazon S3 als Datenspeicher
Amazon S3 steht für Simple Storage Service und ist ein skalierbarer und Web-basierter Objektspeicher-Service. Der Service ermöglicht das Sichern und Archivieren von unbegrenzten Datenmengen und Anwendungen. Jede Art von Datei kann auf S3 abgelegt werden. Aufgrund der Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung eignet sich S3 für eine Vielzahl von Anwendungsfällen wie z. B. Data Lakes, Datensicherung, Ausführung cloudnativer Anwendungen und Datenarchivierung.
S3 speichert Daten als Objekte in sogenannten Buckets. Bei Buckets handelt es sich um Container, die eindeutig sind und beliebig viele Dateien enthalten können. Jedes Objekt besteht aus Daten, Metadaten und einem Schlüssel. Die Daten können ein Bild, ein Video, ein Textdokument oder ein beliebiger anderer Dateityp sein. Die Metadaten enthalten Informationen über die Daten selbst, wie Content-Typ, Datum, Objektgröße etc. Der Schlüssel eines Objekts ist eine eindeutige ID, die an die Bucket-URL angehängt wird. Auf Objekte können Berechtigungen erstellt werden, um den Zugriff auf diese zu bestimmen.
Unsere Lösung zur Anonymisierung von Daten
Um die Daten anonymisiert bereitstellen zu können, werden jetzt für beide Datenquellen je ein DataBrew-Job eingerichtet, der irrelevante Spalten herausnimmt, die sensibeln Daten maskiert und in einen weiteren S3 Bucket ablegt. Aus diesem S3 Bucket werden dann automatisch die anonymisierten Kundendaten der Reporting-Software zur Verfügung gestellt.
AWS Glue DataBrew 3 als Datenanonymisierungstool
AWS Glue DataBrew ist ein visuelles Datenaufbereitungstool (ETL-Tool), mit dem Daten bereinigt und normalisiert werden können, um sie für die Verwendung im Bereich Analyse, Reporting oder Machine Learning vorzubereiten. Es kann aus über 250 vorgefertigten Transformationen gewählt werden, um Datenaufbereitungsaufgaben zu automatisieren. So können z. B. automatisiert Anomalien herausgefiltert und Daten in Standardformate konvertiert – oder eben maskiert – werden.
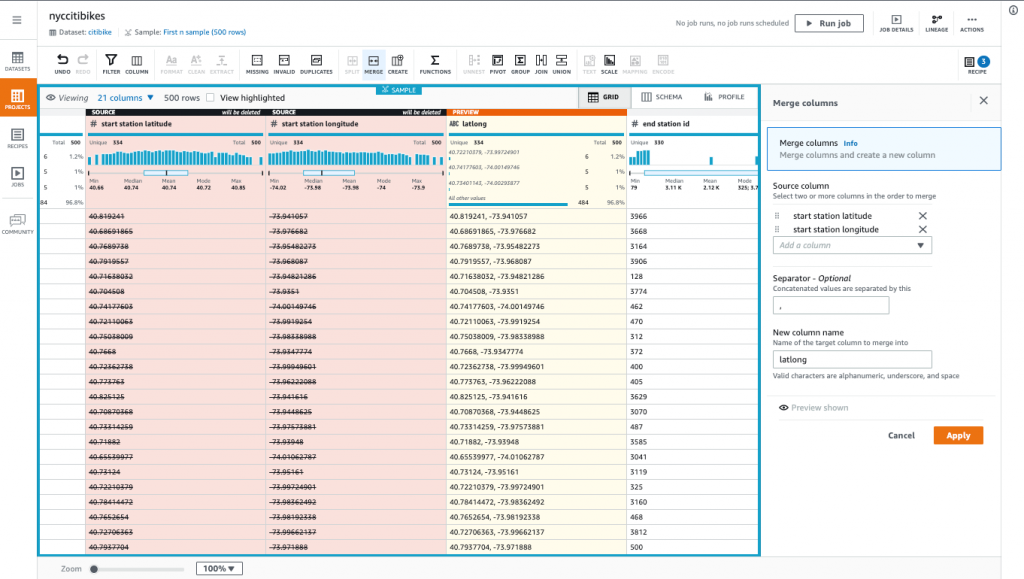
Solche Datentransformationen werden in sogenannten Recipe Jobs definiert. In dem Fall einer Maskierung werden also die Zeichen des betroffenen Datums mit einem speziellen Zeichen, z. B. dem ‘#’ ausgetauscht. Typischerweise werden die aufbereiteten Daten dann in einem S3 Bucket zur weiteren Verwendung abgelegt. Mehr Informationen zu AWS Glue DataBrew können im Developer Guide gefunden werden.
Umsetzung mit DataBrew
Bei der Umsetzung machten die wenig aussagekräftigen Fehlermeldungen etwas Probleme. Am Ende stellte es sich heraus, dass es an fehlenden bzw. unzureichenden Berechtigungen gelegen hat. Für DataBrew muss nämlich eine Rolle erstellt und zugewiesen werden, die auf die S3 Buckets für die Rohdaten lesenden bzw. für die anonymisierten Daten lesenden und schreibenden Zugriff erlaubt.
Ein weiteres Problem war, dass es sich bei DataBrew um ein Tool handelt, dass für Datenanalysten gedacht ist, die ihre Reports über eine Oberfläche zusammenstellen. Es ist aktuell nicht möglich, wie anderenorts in der AWS Welt, die Konfiguration der DataBrew Ressourcen über bereitgestellte SDKs für CDK (AWS Cloud Development Kit) zu hinterlegen. Das bedeutet, dass im Falle einer Einrichtung jeder weiteren Umgebung bzw. einer Wiedereinrichtung die gewünschte Datenaufbereitung jedes Mal wieder manuell erstellt werden muss.
Unser Fazit zur Anonymisierung von Daten mit AWS DataBrew
AWS DataBrew hat sich als ein mächtiges Tool zur Datenaggregation herausgestellt. Es ist zwar etwas langsam. Das spielt aber bei einem nächtlichen automatisierten Durchlauf keine weitere Rolle. Zudem ist es recht kostengünstig. Für einen täglichen Durchlauf von zweimal knapp 40.000 Datensätzen werden ca. 10 US$ im Monat fällig. Dafür kann man die oben erwähnten Probleme gerne in Kauf nehmen. Wir sind also recht zufrieden mit unserer Lösung für die Anonymisierung von Daten und würden bei ähnlichen Problemstellungen sicherlich wieder zu AWS DataBrew greifen.








